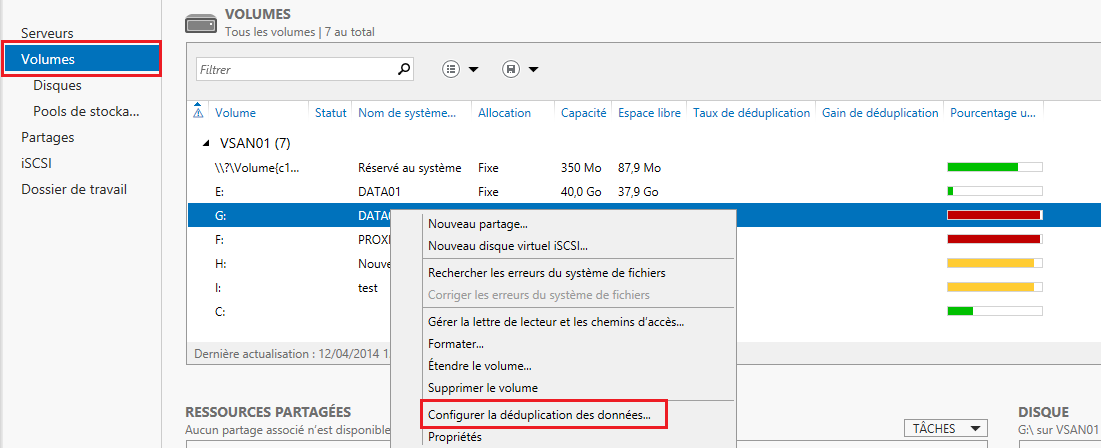
Bonjour à tous,
Je vais m'attaquer à plusieurs articles qui seront liées au stockage sous Windows Server 2012 R2.
Nous allons voir dans un premier temps la déduplication de données, son fonctionnement et un test sous Windows Server 2012 R2.
Ensuite, je vous montre la configuration et la mise en place de la déduplication. (qui sera dans la partie 2 )
PARTIE 1 DEDUPLICATION - Fonctionnement :
Les nouveautés dans Windows
Server 2012 R2 :
1- Introduction déduplication :
La déduplication en quelques
mots, existe depuis de nombreuses
années, mais peu connu encore, Microsoft a décidé de l’intégrer dans son système
d’exploitation Windows Server 2012 et 2012 R2.
Avec la déduplication les DSI
vont pouvoir régler un problème de taille, qui est l’explosion des données, aujourd’hui dans les systèmes d’information, nous avons trop de données :
- Serveur de
fichiers
- Donnée des
utilisateurs
- Archives
- Backup (des VM,
etc )
- Fichier des VM ..
- Logiciels etc
La déduplication permet de stocker
d’avantage de données en moins d’espace.
En simplifiant la chose, le fonctionnement
de la déduplication :
Il y’a une segmentation de
fichiers en petit morceaux de taille variable (32-128 Kb), les doublons sont
identifiés et gardés en une seule copie, ils sont compressés, puis mis dans des
fichiers spéciaux.
Illustration en image :
On
voit bien ici, les données après activation de la déduplication, sont stockées
qu’une seule fois , ils sont compressées et placées dans des fichiers spéciaux. Il
y’a une création de référence afin d’éviter les doublons
La
déduplication permet de segmenter les données stockées, ainsi, les données se
voient attribuer un identifient unique,
cela va permettre de comparer les identifiants des autres données stockées, si
l’identifient est unique, il est stocké directement sur l’espace de stockage.
Par
contre, si on stocke des données à nouveau et que lors de la vérification, on
se retrouve avec un identifiant similaire, (donc il y’a doublon de données),
ces données-là ne seront pas stockées sur l’espace de stockage, mais il y’aura
une référence (pointeur) vers les données existantes, afin d’éviter les
doublons.
Et cela permet de faire un
gain d’espace énorme, voici une étude réalisée dans les laboratoires de Microsoft
qui montre les gains qu’on peut avoir dans un environnement de
production :
Voici un tableau provenant de TechNet qui résume également
les gains d’espace de stockage possible grâce à la déduplication dans Windows
Server 2012 R2 :
Cependant, il y’a des scénarios
ou il est déconseillé d’utiliser la déduplication, nous allons voir dans quel
cas il sera possible d’utiliser la déduplication et inversement.
Les volumes doivent être formaté en NTFS.
Déduplication avec Windows Server 2012 R2:
Scénario idéal pour la déduplication :
- Partage de déploiement
binaire (logiciels)
- Serveur de
fichiers
- Supporté également
avec les Storage CSV utilisé dans des SOFS
- Environnement de
virtualisation / VDI
- Librairies de
virtualisation (SCVMM)
Scénarios non conseillés :
- Serveur SQL server
- Exchange Server
- Disque Système
(disque de boot)
- 2 Mise en place de la déduplication
Avant d’appliquer la
déduplciation au sein de vos serveur Windows Server 2012R2, il est conseillé
d’évaluer la quantité de stockage que vous allez gagner grâce à la
déduplication, il existe un petit outil très sympa (DDPEVAL.exe)qui va vous aider à évaluer
cela et chiffrer les gains possibles après la déduplication.
Pour cela, il faut installer
la fonctionnalisé déduplication de données sur le (les) serveur :
Une fois que la fonctionnalité
est installée, vous allez pouvoir utiliser l’outil d’évaluation ==> DDPEVAL.EXE
Ouvrez une fenêtre PowerShell
Voici la syntaxe général ==> DDPEval.exe <lettre disque > /<répertoire
de donnée>
Et tapez la syntaxe
suivante :
ddpeval.exe E:\data
Voici un exemple que j’ai
effectué au sein de l’un de mes serveur de stockage : (sous Windows Server
2012 R2).
Une fois que j’ai lancé la
commande, l’outil procède à l’évaluation du gain de stockage qu’on peut
obtenir :
Je vais vous prouver
l’efficacité de la déduplication au sein de Windows Server 2012 R2 :
J’ai dans le dossier E:\DATA 3
fichiers avec un total de 1.14 Go.
Voici l’illustration :
Je copie ces trois fichiers deux fois dans le même dossier et
j’aurais donc 9 fichiers avec une taille totale d’espace disque consommée qui
est environ de 3.44 Go. (1.14 * 3 = 3.42)
Voici l’illustration :
Je vais appliquer l’outils d’évaluation de dédplucation de
données à mon disque E:\data et nous allons voir ce qui va se passer :
Voici la commande : DDPEval.exe E:\data
Voici le résultat
de l'évaluation :
On voit que 9 fichiers ont été
traités, c’est bien le nombre de fichier que j’ai dans le dossier E:\data.
Avec la même Taille de départ 3.44 Go.
La
dédpulication repère qu’il y’a donc des doublons, (même identifiant au sein des
données), donc elle optimise le tout et stocke la donnée qu’une seule fois, et
on va se retrouver donc avec seulement les 3 premiers fichiers qui seront
stockés dans le disque, les deux autres copies ne seront pas stockés, mais seront
accessibles via des références qui vont pointer vers les 3 fichiers originaux.
Cela
se vérifie, car la taille optimisé sera de 1.07
Go, ce qui correspond bien à la taille de départ des trois fichiers (1.14 Go).
Le gain de stockage avec la déduplication dans ce cas sera de 2.36 Go, c’est-à-dire 68 %.
Cela
se vérifie car si on fait 1.07+2.36 =
3.44 et 3.44 est bien la valeur de départ des 9 fichies de départ.
Voila, la première partie est finie, nous verrons dans un prochain article la mise en place et la configuration de la déduplication de données au sein de Windows Server 2012 R2.
@ bientôt Seyfallah Tagrerout